TL;DR: A simple yet effective method of improving fine-tuned diffusion models by leveraging the unconditional priors from its base model.
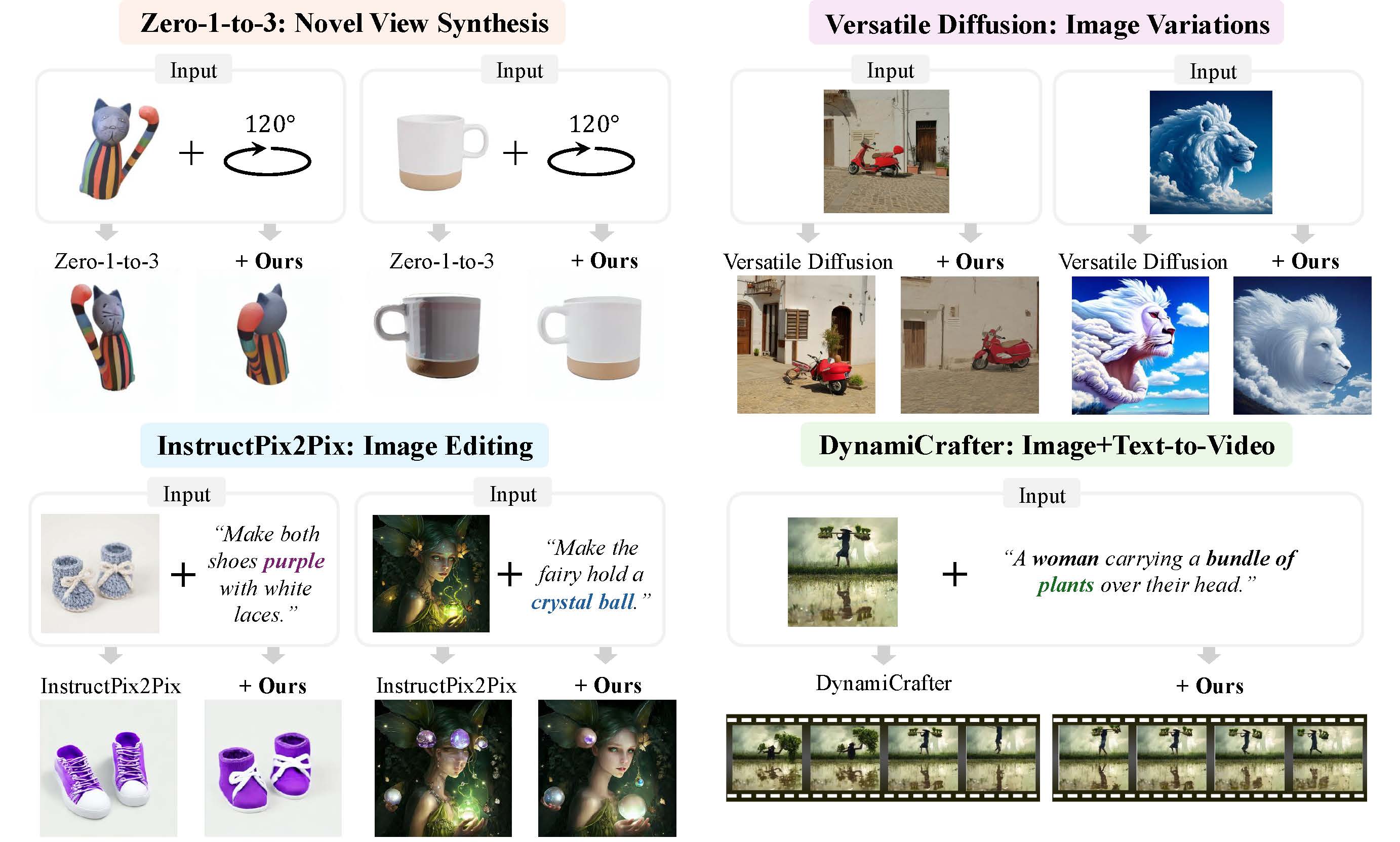
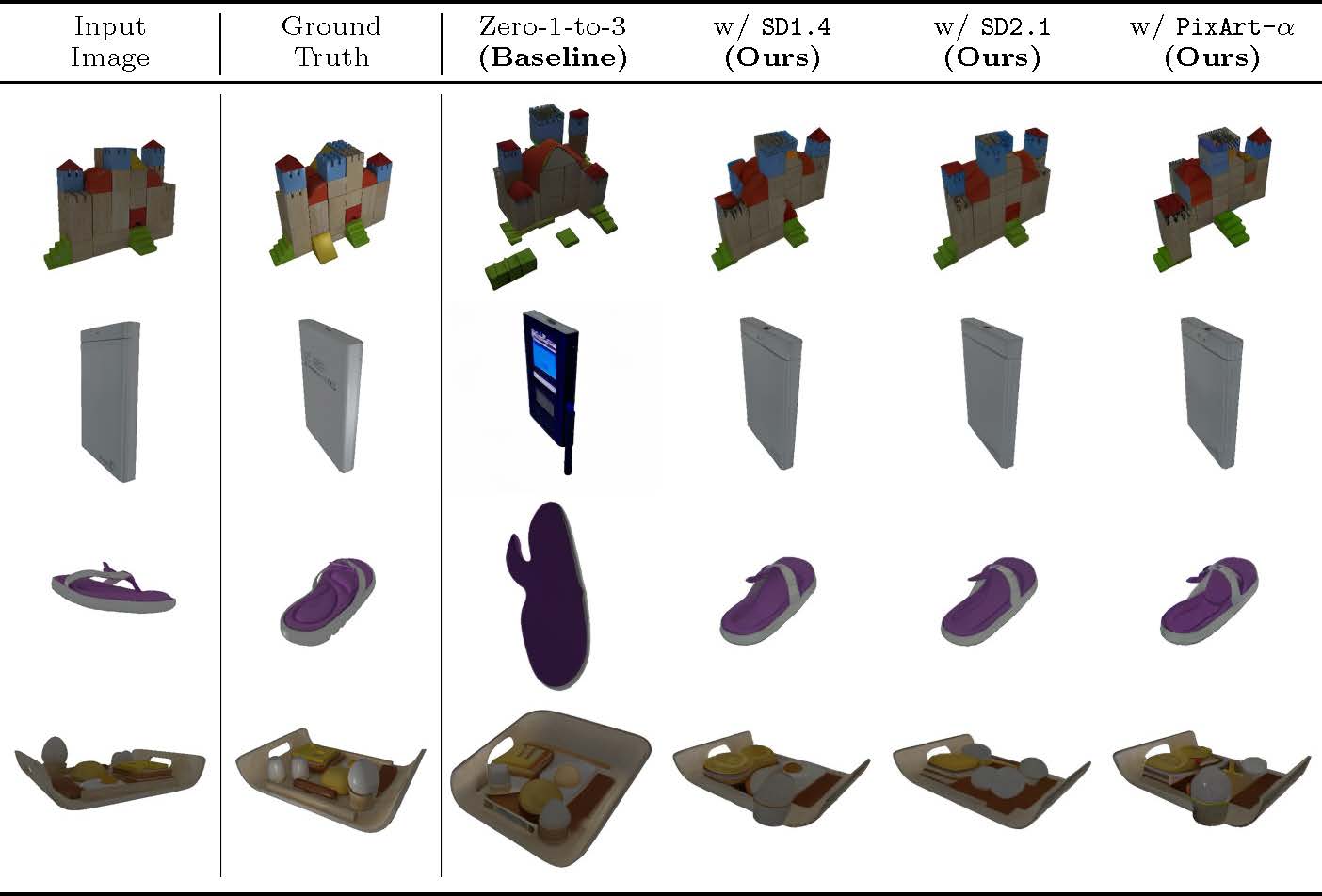
Classifier-Free Guidance (CFG) is a fundamental technique in training conditional diffusion models. The common practice for CFG-based training is to use a single network to learn both conditional and unconditional noise prediction, with a small dropout rate for conditioning. However, we observe that the joint learning of unconditional noise with limited bandwidth in training results in poor priors for the unconditional case. More importantly, these poor unconditional noise predictions become a serious reason for degrading the quality of conditional generation. Inspired by the fact that most CFG-based conditional models are trained by fine-tuning a base model with better unconditional generation, we first show that simply replacing the unconditional noise in CFG with that predicted by the base model can significantly improve conditional generation. Furthermore, we show that a diffusion model other than the one the fine-tuned model was trained on can be used for unconditional noise replacement. We experimentally verify our claim with a range of CFG-based conditional models for both image and video generation, including Zero-1-to-3, Versatile Diffusion, DiT, DynamiCrafter, and InstructPix2Pix.

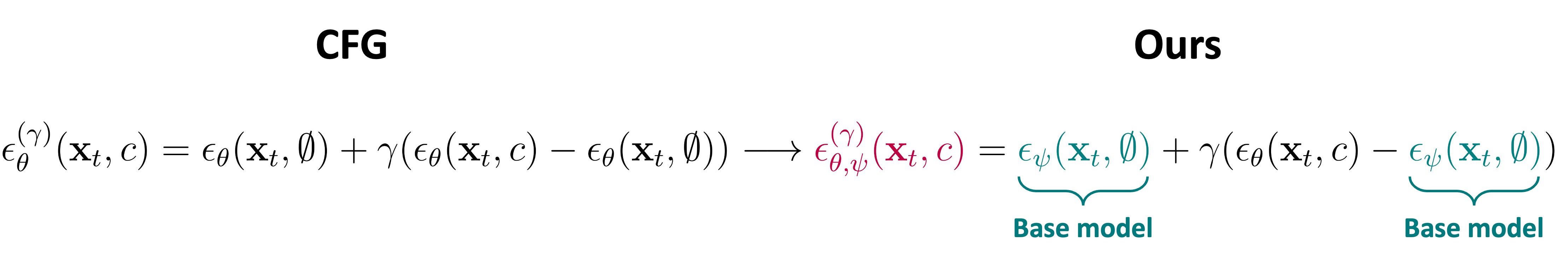


"A woman carrying a bundle of plants over their head.”
"A group of people riding bikes down a street.”
"A man in a black suit and a sombrero, shouting loudly.”



"A couple of horses are running in the dirt.”
"A man sitting on steps playing an acoustic guitar.”
"Two women eating pizza at a restaurant.”

We thank Juil Koo for providing constructive feedback of our manuscript.
@misc{phunyaphibarn2025unconditionalpriorsmatterimproving,
title={Unconditional Priors Matter! Improving Conditional Generation of Fine-Tuned Diffusion Models},
author={Prin Phunyaphibarn and Phillip Y. Lee and Jaihoon Kim and Minhyuk Sung},
year={2025},
eprint={2503.20240},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.20240},
}